
新鲜出炉!探索三个炫酷AI项目

一、陌陌的一个惊喜
陌陌开源了三个令人赞叹的AI项目,你们还只关注GPT吗?让我来告诉你们Meta在GitHub上开源的这三个项目。
首先是Meta推出的AI生成音乐模型,名叫Audiocraft。这个厉害的Python库利用AI生成音乐,而且没有侵犯版权哦!它使用的是一个叫MusicGen的生成模型,是一个单级子回归的Transformer模型。它经过32kHz EnCodec分词器的训练,具备4个以50Hz采样的码本。与谷歌的MusicLM方法不同,MusicGen不需要自我监督的语义表示,一次生成就能产生四个码本。未来或许我们会在音乐领域挥洒才华,文生图、文生文之后,音乐的创作或将掀起一场革命。
二、Diffusers迎来重磅更新
Diffusers推出了0.17.0版本的重大更新!根据更新报告了解到,该版本改进了LoRA、Kandinsky、Torch编译加速等特性。Diffusers到底是什么呢?它是一个著名的训练扩散模型,常用于生成图像、音频,甚至用于生成更多细节,例如分子的3D结构。它的使用非常简单,一般以模块化工具箱的方式提供技术支持。它的设计注重可用性和可定制性,并提供三个核心组件,由Hugging Face免费开源。使用ControlNet进行快速训练后,可以得到进一步提升的效果和质量。Diffusers的可能性无限,让我们拭目以待吧!
三、万物皆可识别
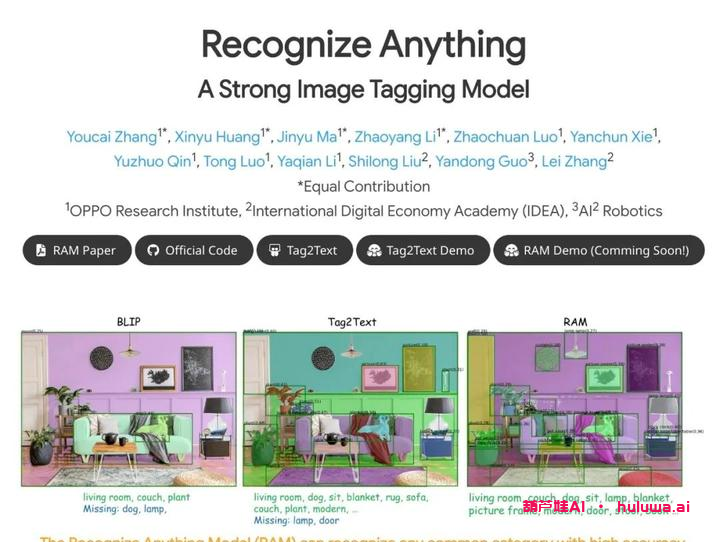
中国的开源项目——Recognize Anything Model(RAM)如火如荼地发展着,它是用于图像标记的一种强大基础模型。这个项目由复旦大学联合OPPO研究院和国际数字经济学院合作开发。最早Meta在GitHub上开源的一个用于自动实现图像切割的模型,名为Segment Anything Moedl,虽然在图像定位方面表现出色,但在图像识别方面却平平无奇。于是,便有了我们现在的RAM。根据介绍,这个模型采用了一种全新的图像标记方法,可以高精度地识别任何常见类别的图像,并利用大规模图像文本进行训练,而不是手动注释。RAM的开发包括四个关键步骤:通过自动文本语义解析大规模获取无注释图像标签;利用统一标题和标记训练初步模型进行自动注释,分别由原始文本和解析标签监督;利用数据引擎生成额外注释并清除不正确的注释;利用经处理的数据对模型进行再训练,并使用更小但质量更高的数据集进行微调。通过多项基准测试评估,我们看到RAM的标记能力非常出色,效果明显优于CLIP和BLIP。令人瞩目的是,RAM甚至超越了完全监督的方式,与Google API媲美。此外,该项目还提供了一个名为Tag2Text的工具,可以直接为图像中的特定对象生成标签。如果结合Meta开源的SAM模型,甚至可以批量移除图像中的指定对象,进一步提升处理效率。
总结
陌陌开源的音乐生成模型Audiocraft、Diffusers的重磅更新和国内开源项目RAM都给科技界带来了新的突破和可能性。这些项目展现了AI技术在不同领域的创新应用,为我们带来了更多惊喜。期待它们未来带来更多的惊艳表现!快来体验吧!
感谢你们的阅读!让我们一同探索科技的无限可能!
















暂无评论内容