
CHATGPT训练教程:自己训练一个属于你的聊天机器人

①、准备数据集
训练聊天机器人的第一步是准备好数据集。你可以使用类似于instruct的方法来构造指令数据集结构。比如,你可以直接使用开源的中文数据集:Chinese-alpaca-lora。
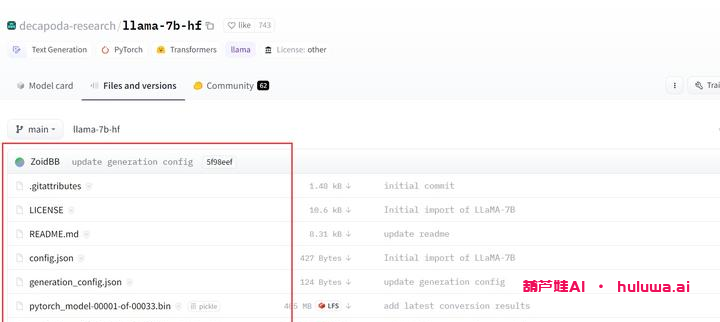
②、下载开源代码
你可以下载Alpaca-LoRA的代码,然后将数据集放到alpaca-lora目录下。确保你的python环境配置正确,并安装所需的依赖库。

③、开启训练
在开始训练之前,你需要先下载LLaMA基础模型,可以去huggingface上进行下载。由于国内有限制,你可能需要逐个下载所有文件,并将其放到llama-7b-hf目录下。
接下来,执行训练模型的命令。训练完成后,你就可以看到生成了lora-alpaca-zh模型。
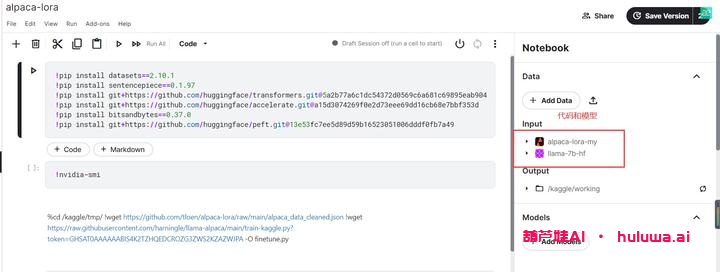
④、云端部署
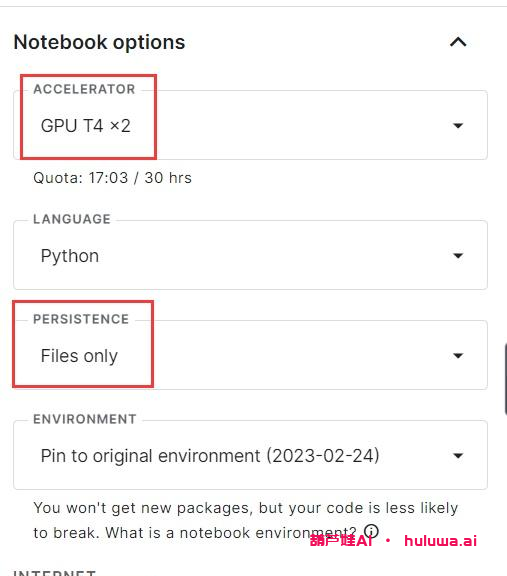
你可以选择将模型部署在云端,比如使用kaggle部署模型。将对应的模型、数据集和代码放到kaggle notebook中,并设置GPU和网络。
保存代码后,点击打开日志中生成的网页,你就可以得到对话网页了。现在,你可以随时随地和你的聊天机器人进行对话了!
汇总
自己动手训练聊天机器人,从准备数据集到开启训练再到云端部署,一气呵成。快来尝试一下,和你的聊天机器人进行一场有趣的对话吧!
感谢你的阅读!快来动手训练你的CHATGPT吧!
想要更多信息?请访问葫芦娃AI
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END
















暂无评论内容