
摘要: 一项新的研究预测,技术公司将在2026年至2032年之间的某个时候耗尽AI语言模型的公开培训数据的供应。
AI语言模型将面临数据短缺挑战
最新研究显示,研究机构Epoch AI发布的一项新研究预测,科技公司将在2026年至2032年之间耗尽AI语言模型的公开可用训练数据。
当公共数据耗尽时,开发者将不得不决定如何为语言模型提供数据。一些想法包括使用现在被视为私人的数据,比如电子邮件或短信,以及使用其他AI模型生成的“合成数据”。
除了训练越来越大的模型,另一条路径是构建更专门用于特定任务的技能训练模型。
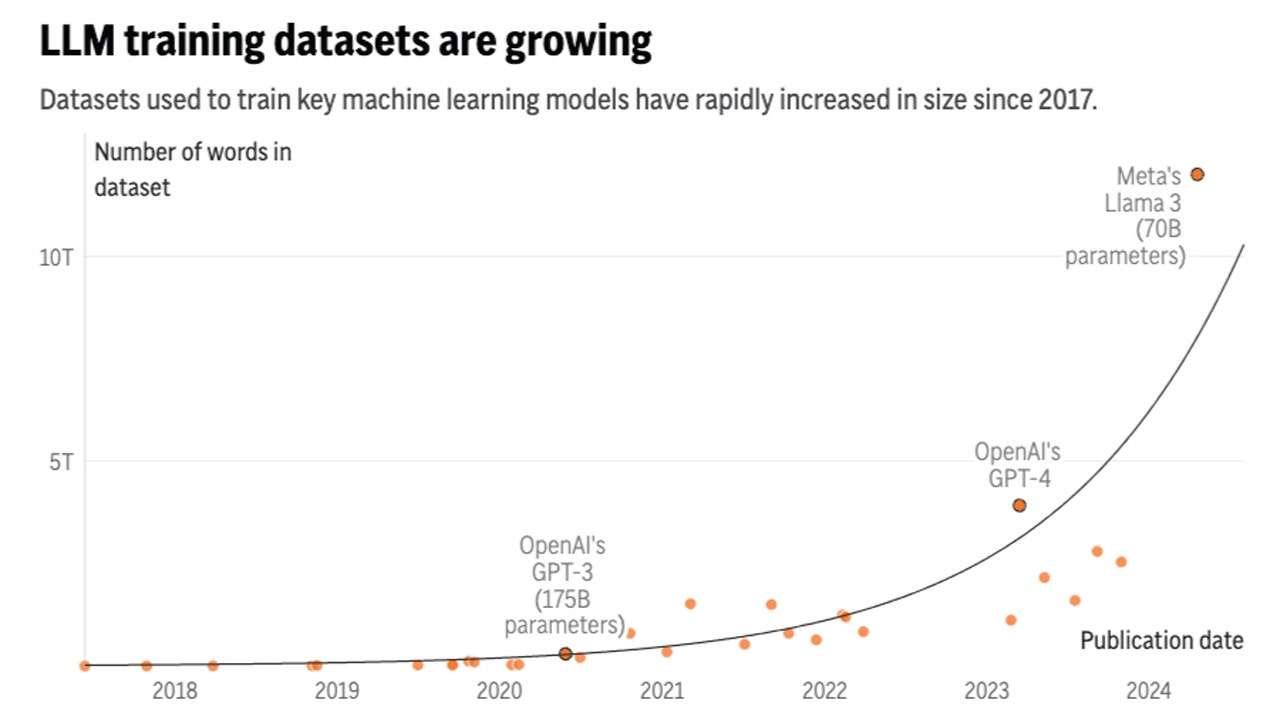
人们担心AI系统如CHAT GPT可能很快会耗尽使它们变得更智能的东西——人们在线上写的数万亿字。
Epoch AI的研究人员最初在两年前做出了他们的预测,当时CHAT GPT刚刚推出,他们在一份工作论文中预测,高质量文本数据将在2026年被耗尽。然而,自那时以来发生了很多变化,包括新技术的出现,使AI研究人员能够更好地利用他们已经拥有的数据,有时在同一来源上多次“过度训练”。
但是有限度,经过进一步研究,Epoch现在预计在未来两到八年内将耗尽公共文本数据。
该团队的最新研究已经经过同行评审,并将在今年夏天的维也纳国际机器学习大会上进行展示。Epoch是由旧金山Rethink Priorities主办的非营利机构,由有效利他主义的支持者资助。
AI研究人员十多年前意识到,大力扩展两个关键因素——计算能力和海量互联网数据——可以显著提高AI系统的性能。
AI语言模型中输入的文本数据每年增长约2.5倍,而计算能力每年增长约4倍。Facebook母公司Meta Platforms最近声称,他们即将推出的Llama 3模型的最大版本已经在多达15万亿个标记上进行了训练,每个标记可以代表一个单词的一部分。
然而,是否值得担心数据瓶颈还有争议。
“我认为重要的是要记住,我们不一定需要训练越来越大的模型,”多伦多大学计算机工程助理教授、非营利Vector人工智能研究员Nicolas Papernot表示。
Papernot表示,构建更专门用于特定任务的AI系统也可以通过训练模型来实现。但他对训练生成式AI系统的相同输出以导致性能下降的问题表示担忧。
如果真正的人工制作句子仍然是关键的AI数据来源,那么管理最受追捧的宝藏的人——如Reddit和维基百科等网站,以及新闻和书籍出版商——已经被迫认真思考它们的使用方式。
“也许你不会砍掉每座山的山顶,”维基媒体基金会首席产品和技术官Selena Deckelmann开玩笑说。她表示,她希望人们继续有动力继续贡献内容,特别是在廉价和自动生成的“垃圾内容”开始污染互联网的情况下。
AI公司应该“关注人类生成内容如何继续存在并继续可访问,”她说。
Epoch的研究称,付费数百万人来生成AI模型所需的文本“不太可能是一种经济推动技术性能提升的方式”。
随着OpenAI开始着手培训下一代GPT大语言模型,首席执行官Sam Altman在上个月的联合国活动中告诉观众,该公司已经尝试“生成大量合成数据”进行训练。
“我认为你需要的是高质量数据。有低质量的合成数据。有低质量的人类数据,”Altman说。但他也对过度依赖合成数据而不是其他技术方法来改进AI模型表示担忧。
“如果训练模型的最佳方式就是生成象征性数据的千亿标记并将其反馈回去,那将非常奇怪,”Altman说。“在某种程度上,这似乎是低效的。”














暂无评论内容