
在 Stock Photo 一章中,介绍了 img2img 的方法,这个方法除了解决 Stock Photo 的那几个问题外,还很适合多个场景。
本章会着重介绍用这个方法生成的头像的 prompt。并且从本章开始会逐步丰富我们的 prompt 结构,使其更加完整。
注意事项
在介绍 img2img 的应用前,我想强调一下:
- 不要在 Discord Midjourney 公开群上传自己的照片!这样你的照片会被公开群里的所有人看见。建议使用 Midjourney Bot。
- 另外,非 pro 付费会员,生成的图片都会被其他会员看见。但你可以在生成完头像后,删掉生成的图片。如果还不知道如何使用 Bot ,及删除照片,请看基本操作篇。
- img2img 的操作我就不过多赘述了。如果你还不太清楚,可以看基本操作篇,以及 Stock Photo 那篇。
3D 卡通头像
第一个要分享的是卡通头像。首先跟大家强调下:
- 我基本上把国内国外的生成头像教程都看过,并试过一遍,还跟 Midjourney 社群的人也交流过。我的理解是,以目前 V5 的能力,不管你如何调整 prompt ,想用 img2img 方法生成一张非常像原图的图片,基本靠运气,即使用了前面介绍的技巧七方法,也只是提高概率。如果你有令头像非常像的方法,不妨通过 Issue 分享给我,我会署下你的名字,并分享给大家。
- 各位在学习的过程中,如果发现生成的图片不像原图,也不需要气馁。这是正常的。
- 你可以通过我分享的方法,生成一张有原图神韵的卡通头像。注意肯定不会非常像原图。
在 prompt 里加上原图链接(建议使用证件照,或者背景比较单一的照片,这样成功率会高一些),然后用我前面提到的框架设计一个 prompt:
| Prompt | 解释 | |
|---|---|---|
| 类型是什么? | Portraits / Avatar | 如果你的原图是证件照,可以在 prompt 里加入「肖像」一词,或者「Avatar 头像」。 |
| 主体是什么? | smiling cute boy, undercut hairstyle | 这里可以是选填,你可以先不加这个描述,只填其余 prompt,然后如果生成的图片不像你。那你就在这里加点描述下你的头像的词,一般就是性别、样貌、发型、配饰(比如眼镜、耳环等)、表情等。注意,尽量挑特征比较强的部分输入,特征对了,生成的图片基本会有几份像。 |
| 背景是什么? | white background | 我这里保留了证件照的白底,你可以加一些实际场景的背景,比如餐厅之类的。 |
| 构图是怎样的? | null | 因为我们预先传了图片,图片是张证件照,所以不填 |
| 用什么镜头? | soft focus | 柔焦是指摄影中,使用柔焦镜头,使得拍摄的影像既清晰又柔和的效果。一般多在拍摄人像的时候使用,我在 prompt 里加上这个,可以使照片更柔和。你也可以不加。 |
| 是什么风格? | 3d render,Pixar style | 因为目标是生成 3d 照片,所以这里加了 3d render(3d 渲染),以及我喜欢的皮克斯风格 |
| 参数 | —iw 2 | iw 是一个文字和 img 权重参数。数值越大,就越像原图,关于这个值的介绍,可以看高级参数篇。 |
最后,还有三个技巧:
- 如果你生成的照片并不像预设的照片,可以在四张图里,挑一张比较像的,然后点 V(Variation),让模型继续生成,再继续挑一张像一点的照片,然后继续生成新照片,直到出现一张比较像的。
- 第二个,我觉得很神奇,如果前两个方法你都试过了,你生成的图片还是跟原图不像,那就在 prompt 里加上「wear glasses(戴眼镜)」,真的很神奇,我只要加上戴眼镜就像非常多,如果你原图戴眼镜了,你试试在参数里加个 —no glasses,你会得到一张更不像你的图。
- 最后,就是多用一个参数,这个方法会在技巧八中展开说下。
本章最后,有我的证件照的案例。
技巧七:多参数同时使用
在使用 img2img 的方法生成头像时,我发现问题是「文字权重比图片权重高」,导致其生成的图片不像原图,iw 参数在 V5 里最多提升图片权重到 2,所以我就在想有没有可能进一步降低文字的权重。
然后我就试了下 s 参数,发现的确好了很多。
如果生成的图片还是不像,你可以在 —iw 2 基础上,再加一个参数 —s 200 ,注意同时用两个参数时,中间不要有逗号。我发现加了 s 参数之后的确像了很多,我个人猜测是 s 和 iw 连用会进步一削弱 text 的权重。
s 是控制生成图片的风格化程度。简单理解,这个值越低会更符合 text prompt 的描述,数值越高艺术性就会越强,但跟 text prompt 关联性就会比较弱。所以如果你生成的图还是不像,就加大这个值,比如调到 500。
我想通过这个案例告诉大家,多个参数一起使用,有可能会形成合力,进一步放大模型的能力。未来有新的参数能力,不妨也想想有没有可能一起用?
动漫风头像
与 3D 卡通头像一样,主要的修改是在图片风格上:
| Prompt | 解释 | |
|---|---|---|
| 类型是什么? | Portraits / Avatar | 继续使用相同描述 |
| 主体是什么? | smiling cute boy, undercut hairstyle | 继续使用相同描述 |
| 背景是什么? | white background | 继续使用相同描述 |
| 构图是怎样的? | null | 继续使用相同描述 |
| 用什么镜头? | null | 因为是漫画风,就不加柔光镜头了 |
| 是什么风格? | anime, Studio Ghibli | 目标是制作动漫风的头像,所以这里加了 anime(动漫),然后加了吉卜力风格 |
| 参数 | —iw 2 —s 500 | 注意同时用两个参数时,中间不要有逗号。 |
赛博朋克头像
这是我最喜欢的风格之一,也是只需要改一下风格和背景即可:
| Prompt | 解释 | |
|---|---|---|
| 主体是什么? | cyberpunk robot face, holographic VR glasses, holographic cyberpunk clothing | 加了脸的修饰,还有戴上 VR 眼镜,穿上赛博朋克风衣服 |
| 背景是什么? | neon-lit cityscape background | 为了让图片更像是赛博朋克,就加了个霓虹灯城市背景,让其看起来更有赛博那味 |
| 是什么风格? | Cyberpunk, by Josan Gonzalez | 加了赛博朋克风格,以及我非常喜欢的赛博朋克画家 Josan Gonzalez |
上面这几个头像 prompt 最后生成的头像是这样的,坦率地说,我已经尽力了,我的个人特征太少了,人也不帅,生成的图片,都有种东南亚人那味,感觉 Midjourney 对亚洲人的理解还不是很行 😂

技巧八:使用 Seed 参数对图进行二次修改
注意:这个技巧,我个人觉得未来潜力比较大,但目前 Midjourney 的实现效果还比较一般,效果得不到保证。官方的社区的帮助文档也提到这个功能在 V5 非常不稳定。详细可以看看我整理的 Midjourney 官方 FAQ 一章。
你可能遇到类似这样的场景:
- 你输入一段 prompt,机器生成了 4 张图片
- 你看了下4张照片,发现其中有一张还行,但其余不是很满意,然后改了下 prompt,机器又生成了一些
- 但这次生成的照片你都不满意,你就很烦恼为何会这样
- 然后你就像为啥不能在第一次生成图上做修改呢?
基于某一次生成的结果进行二次 prompt 修改,理论上我认为是可以的,以赛博朋克头像为例,我先用上述 prompt 生成了四张图片,然后在消息的右上角点击 emoji 按钮(下图1),然后再输入框里(下图2)输入 envelope,然后点击信封 emoji(下图3),接着 bot 就会将 seed 号码发给你。
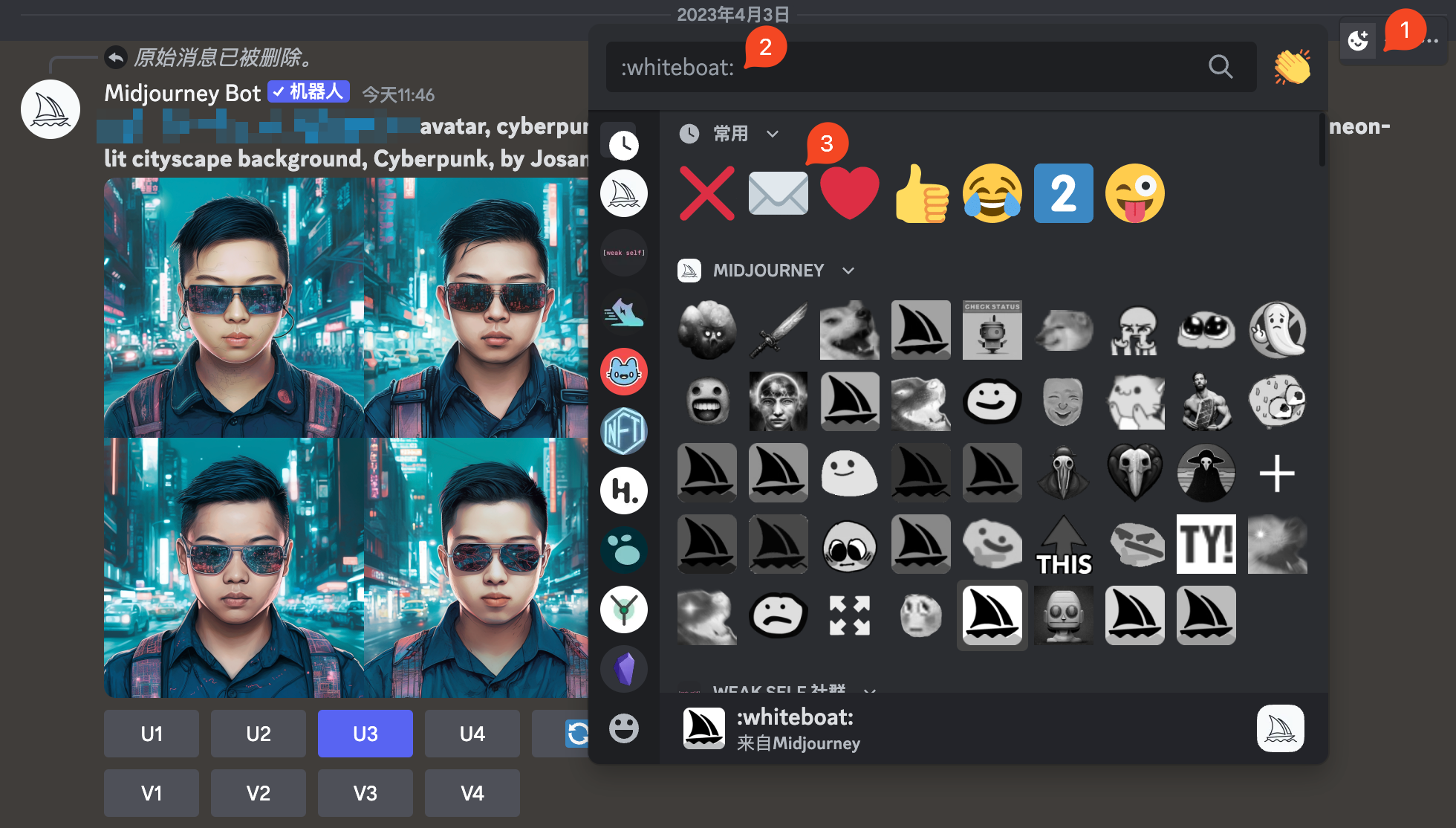
然后我修改上面的赛博朋克头像的 prompt,将其背景改为 China Town,此时需要注意:
- 新的 prompt 并不是只改 background,你需要将之前的 prompt 都带上。
- prompt 仅修改 background 的部分。
- 最后带上 seed 参数。
以下是我的案例:
原 prompt:
{img url} avatar, cyberpunk robot face, holographic VR glasses,holographic cyberpunk clothing, neon-lit cityscape background, Cyberpunk, by Josan Gonzalez --s 500 --iw 1
新 prompt(seed 码只是示例,你要填写自己的 seed):
{img url} avatar, cyberpunk robot face, holographic VR glasses,holographic cyberpunk clothing, China Town background, Cyberpunk, by Josan Gonzalez --s 500 --iw 1 --seed 758242567
以下是生成的效果(左图为原图,右图是用了 seed 后生成的图),可以看到,背景的确换了,但人的外观也有点变化 😂
效果不是很好,但我觉得值得探索,这样能提高渐进优化的成功率:

技巧九:神秘的 blend 功能
这个技巧,说实话,我感觉不能称其为技巧,但这又是一个 Midjourney 非常重要的 feature,所以在这里着重介绍一下。
这个功能使用起来非常简单,在 Discord 输入框里 /blend,然后点击这个菜单:
![图片[4]-葫芦娃AI-一起学AIMidjourney使用场景5:头像-葫芦娃AI-一起学AI葫芦娃AI](https://huluwaai.com/wp-content/uploads/2023/05/d5e3a-MJ057.png)
之后你的输入框就会变成这样:
![图片[5]-葫芦娃AI-一起学AIMidjourney使用场景5:头像-葫芦娃AI-一起学AI葫芦娃AI](https://huluwaai.com/wp-content/uploads/2023/05/4ab26-MJ058.png)
然后你就可以点击这两个框,然后选择你电脑上的照片,添加完成后,大喊一声「使用融合卡」(不是),然后点击回车:
![图片[6]-葫芦娃AI-一起学AIMidjourney使用场景5:头像-葫芦娃AI-一起学AI葫芦娃AI](https://huluwaai.com/wp-content/uploads/2023/05/ce65c-MJ059.png)
然后 Midjourney 就会生成这样牛逼的结果,左边是融合钢铁侠,右边是融合巴斯光年:
![图片[7]-葫芦娃AI-一起学AIMidjourney使用场景5:头像-葫芦娃AI-一起学AI葫芦娃AI](https://huluwaai.com/wp-content/uploads/2023/05/a4b98-MJ061.png)
这个功能我第一次看到时,我是非常震惊的,以为是小时候看游戏王里主角们使用「融合卡」的那种效果。可惜并不是,这个功能非常不稳定,仅有在满足多个未知条件才能达到上述的效果。
我本来打算用这个方法用于生成头像,但我发现只要用自己的照片,融合其他风格的照片,效果都不太好,目前实验下来效果最好的是名人头像,我的感觉是因为 Midjourney 喂了不少名人的头像给模型,所以这种融合的效果都很好。
但我觉得它真的很适合做头像,将自己的头像跟另一张图片融合一下,就能生成一张不错的图,方便又快捷。可惜目前这个功能感觉还不太好用。
当然这个功能还不仅仅止于此,它还有很多使用场景,在后续会介绍给大家。














暂无评论内容