
摘要: 最常用的AI基准测试尚未改编或更新,以反映专家AY的模型如何使用。

大部分人工智能基准测试告诉我们很少信息
人工智能领域的竞争日益激烈,各家公司纷纷宣称他们的模型在某些方面达到了最佳性能。然而,这些所谓的“最佳性能”到底意味着什么?更重要的是,一个在技术上“表现”比其他模型更好的模型是否在实际使用中会有明显改进?
专业性指标
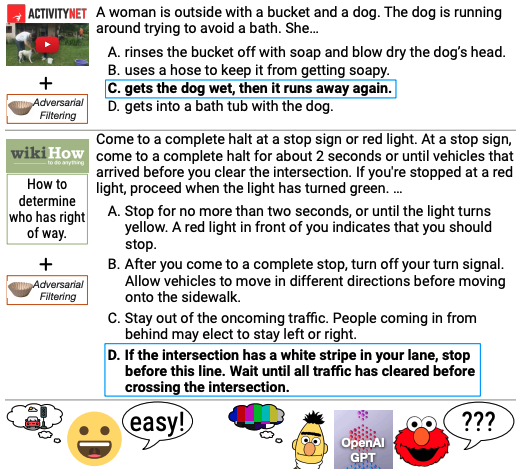
当前人工智能模型最常用的基准测试往往无法准确反映普通人与被测试模型的互动方式。例如,某些基准测试中包含了数百个博士级别的生物学、物理学和化学问题,而大多数人使用聊天机器人的任务更多是回复电子邮件、撰写求职信以及谈论个人感受。
错误和其他缺陷
除了与使用场景不匹配外,一些基准测试是否能够正确衡量其所声称的衡量对象也存在争议。例如,一个用于评估模型常识推理能力的测试发现,超过三分之一的问题存在拼写错误和“毫无意义”的写作。而另一个基准测试则要求模型通过死记硬背来解决问题。
修复问题
基准测试存在问题,但是否可以修复呢?一位科学家认为,更多的人类参与可能是正确的路径。通过让真实用户提问,然后雇佣人员评估模型的回答质量。
另一位研究人员则认为,即使修复了一些明显的错误,基准测试也可能无法为绝大多数生成式人工智能模型的用户提供有用信息。相反,他认为应该关注这些模型的后续影响,以及这些影响对受影响者的意义。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END

















暂无评论内容